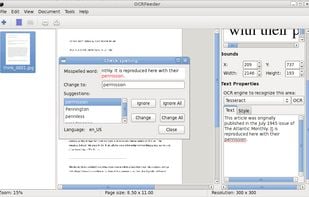
OCRFeeder is a document layout analysis and optical character recognition system.
+1


ZeraBooks is described as 'AI-powered bookkeeping platform that converts bank statements, financial statements, invoices, and checks to Excel with 99.6% accuracy' and is an app in the business & commerce category. There are more than 50 alternatives to ZeraBooks for a variety of platforms, including Web-based, Windows, SaaS, Mac and Linux apps. The best ZeraBooks alternative is Tesseract, which is both free and Open Source. Other great apps like ZeraBooks are Adobe Acrobat DC, ABBYY FineReader PDF, GImageReader and CamScanner.
OCRFeeder is a document layout analysis and optical character recognition system.

Amazon Textract is a machine learning service that automatically extracts text, handwriting and data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables.

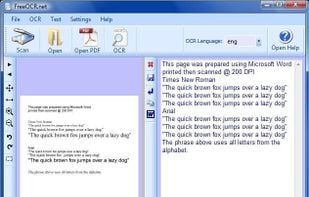
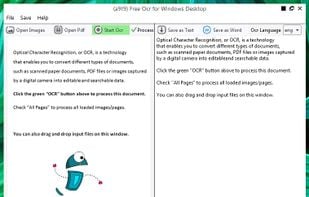
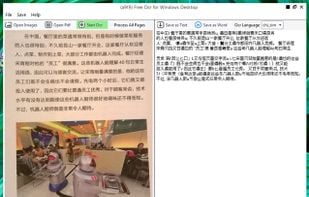
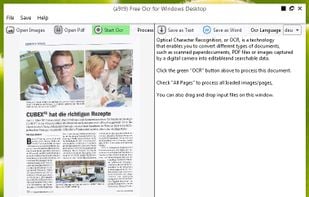
FreeOCR is a scan & OCR program including the Tesseract free ocr engine, also known as a Tesseract GUI. It includes a Windows installer, and it is very simple to use.

Main point of this app is to scan or select existing PDF documents simply using intent or chooser. Other apps require payment to access their api/sdk or simply don't have a possible way to do it. So they rely on switching between an app ,file chooser and a scanner.

OCR software and web service to extract text from image files and PDF. The application is available as online OCR web app, OCR API, or simple to install Windows store application.

Get rid of paper clutter with Stack. Stack is a PDF scanner, document organizer, and detail finder. All in one.

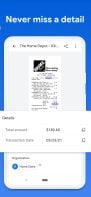

Parse PDF's and update cloud platforms with parsed data, or download your data in Excel, CSV, JSON, & XML. Set up easy parsing rules, based on the layout of your PDF, then automate parsing for future PDF's.
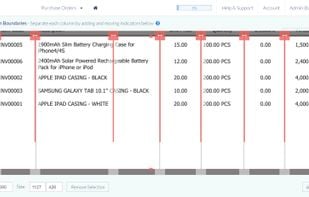

Free Online OCR is a software that allows you to convert scanned PDF and images into editable Word, Text, Excel output formats.
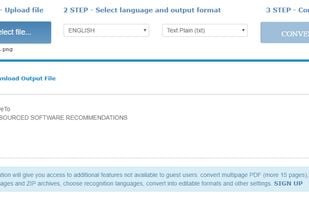

Easy-to-use PDF and email parser. Automatically extract text from emails and PDFs using our powerful OCR engine. Send extracted data to Google Sheet or hundreds of connected CRMs and applications.



Nanonets is an LLM based OCR solution that that automates document processing and data extraction workflows. With models that do not rely on pre-defined document templates, Nanonets helps companies automate document-heavy business processes like accounts payable, order...

OwlOCR offers simple optical character recognition of text in PDF files, images or on-screen and converts that to plain text.

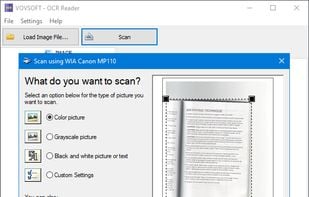
OCR Reader is an image to text converter program that allows you to extract text from PNG, JPEG, TIFF, WEBP, and BMP image files using Optical Character Recognition.