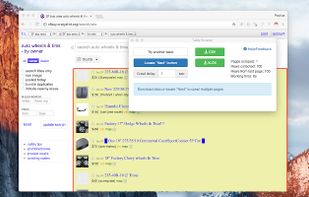
This is an independent DIY search engine that focuses on non-commercial content, and attempts to show you sites you perhaps weren't aware of in favor of the sort of sites you probably already knew existed.
Portia is an open source visual scraping tool, allows you to scrape websites without any programming knowledge required! Simply annotate pages you're interested in, and Portia will create a spider to extract data from similar pages.
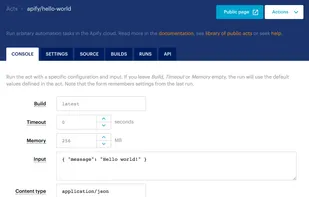
Cloud-based platform for extracting data and automating website workflows, featuring headless browser support, advanced web crawling, reusable code acts and scalable storage.
Minexa.ai is a next-generation tool that makes web scraping faster and more affordable with an AI-powered solution no other alternative has. Unlike others that require constant tweaking, struggle under heavy loads, or charge extra for natural language processing, Minexa adapts...
grab-site is a crawler for archiving websites to WARC files. It includes a dashboard for monitoring multiple crawls, and supports changing URL ignore patterns during the crawl.
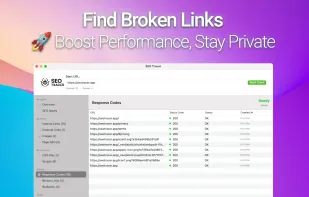
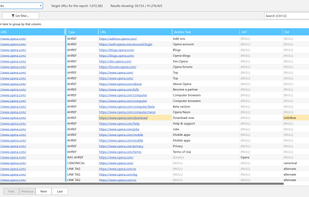
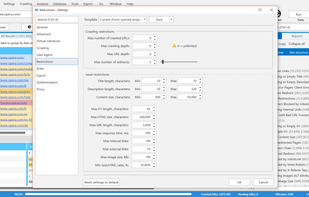
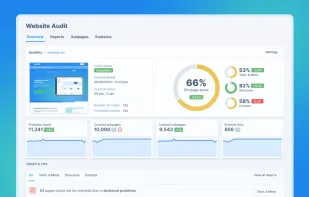
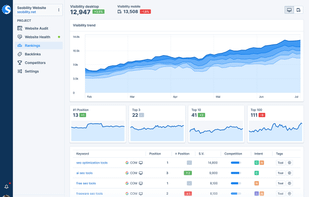
Automated SEO solution offering site audits, on-page optimization, keyword and SERP tracking, backlink monitoring, competitor analysis, and technical issue detection.
This project is a java web spider (web crawler) with the ability to download (and resume) files. It is also highly customizable with regular expressions and download templates.
API for website crawling, scraping, and structured data extraction. Converts web content to markdown or data for AI apps, automates multi-page analysis, and supports custom output formats.
Infatica boasts a global portfolio of residential IPs - over 2,500,000 residential socks5 proxies sourced from real consumers across dozens of countries. Support via tickets, live chat, and phone, with 24-7 response for urgent technical issues.
Pulno is a website audit tool which checks for SEO related issues and sends comprehensible tips to improve on-page SEO with page speed optimizer (CSS and image file optimization), meta tags and unique text analyzer.
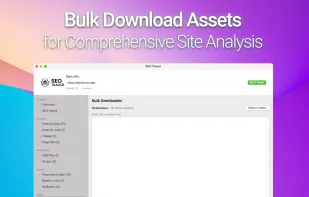
Open-source, extensible crawler for large-scale web archiving, preserves digital artifacts, offers plugin support, distributed crawling, and standardized export formats.
A browser extension that uses AI to detect listings type data which can be easily scraped into CSV or Excel file, no coding required. Can automatically click next button to continue to the next page. The extension runs completely in user’s browser.
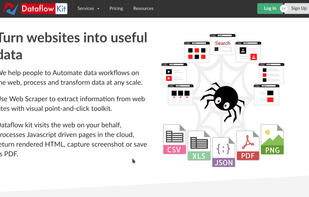
Extract information from web sites with a visual point-and-click toolkit. Turn websites into useful data. Automate data workflows on the web, process, and transform data at any scale.
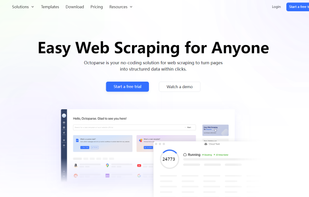
Octoparse is a no-code web scraping tool. It provides both free pre-made scraper templates and custom scraping features with which people without coding knowledge can extract various web data with simple point-and-click.
Asocks is a premium proxy service offering residential and mobile proxies at $3 per GB. It features automatic IP rotation for high stability, a user-friendly interface across platforms, and 24/7 support. Ideal for web scraping, social media management, and market research.
We crawl the web so you don't have to. Our crawlers download and structure millions of posts a day, we store and index the data so all you have to do is to define what part of the data you need.
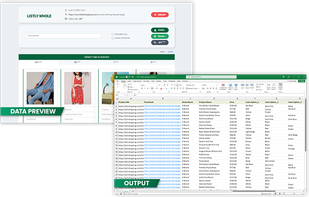
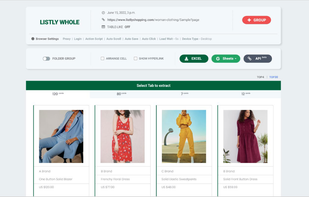
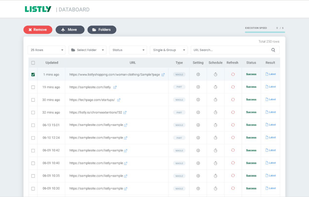
Listly, a web extension, simplifies web scraping without coding. This helps you collect and export enormous volumes of data into either Excel or Google Sheets.
StormCrawler is an open source SDK for building distributed web crawlers with Apache Storm. The project is under Apache license v2 and consists of a collection of reusable resources and components, written mostly in Java.
 SingleFileand
SingleFileand