PDF OCR Alternatives for Linux
PDF OCR is not available for Linux but there are some alternatives that runs on Linux with similar functionality. The best Linux alternative is Tesseract, which is both free and Open Source. If that doesn't suit you, our users have ranked more than 50 alternatives to PDF OCR and ten of them are available for Linux so hopefully you can find a suitable replacement. Other interesting Linux alternatives to PDF OCR are GImageReader, CopyFish, SikuliX and GOCR.
Alternatives list









Cost / License
- Free
- Open Source (GPL-2.0)
Application type
Platforms
- Mac
- Windows
- Linux
- Microsoft Edge
- Google Chrome
- Firefox

 68 SikuliX alternatives
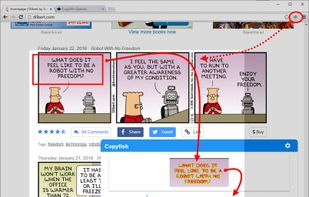
68 SikuliX alternativesSikuliX automates anything you see on the screen of your desktop computer running Windows, Mac or some Linux/Unix. It uses image recognition.
Cost / License
- Free
- Open Source (MIT)
Platforms
- Mac
- Windows
- Linux


GOCR is an OCR (Optical Character Recognition) program, developed under the GNU Public License. It converts scanned images of text back to text files. Joerg Schulenburg started the program, and now leads a team of developers.



A Java/.NET GUI frontend for Tesseract OCR engine. Provides optical character recognition for Vietnamese and other languages supported by Tesseract.


CuneiForm (OpenOCR) is a text recognition software for printed templates. Manuscripts or PDF-files, the program can not recognize, however, but table structures. The language-model is applicable for 20 languages, and the results can be used as HTML, RTF or ASCII text to save, or...



OCRopus(tm) is a state-of-the-art document analysis and OCR system, featuring pluggable layout analysis, pluggable character recognition, statistical natural language modeling, and multilingual capabilities.



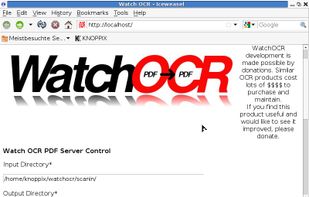
WatchOCR is an open source OCR server that creates searchable pdfs from images in a watched folder.
Cost / License
- Free
- Open Source
Platforms
- Linux